本篇文章会讲解ButterKnife框架的使用(当前版本为8.6.0),注解的概念用法及分类,并且会通过ButterKnife源码学习更加深入的了解注解。
前言
最近略微有点忙,之前说好的RN实践项目和设计模式的文章一度被搁浅😪,我尽量抓紧点时间吧。趁着周末忙中偷闲,来学习下依赖注解框架butterKnife,当前最新版本为8.6.0,源码github地址为这里。
ButterKnife使用
添加依赖
官方使用示例
当然可以使用的注解有很多,下载源码可看到所有可以添加的注解如下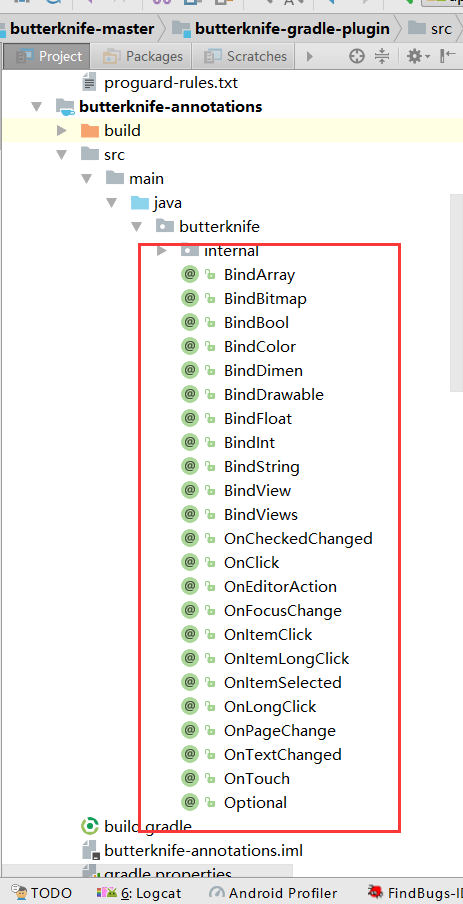
如果以上的注解你觉得使用起来还是不够通畅,还需要在代码中写@bind之类的注解,那么你还可以使用AS插件来辅助注解代码的生成,插件的名字和安装如下图所示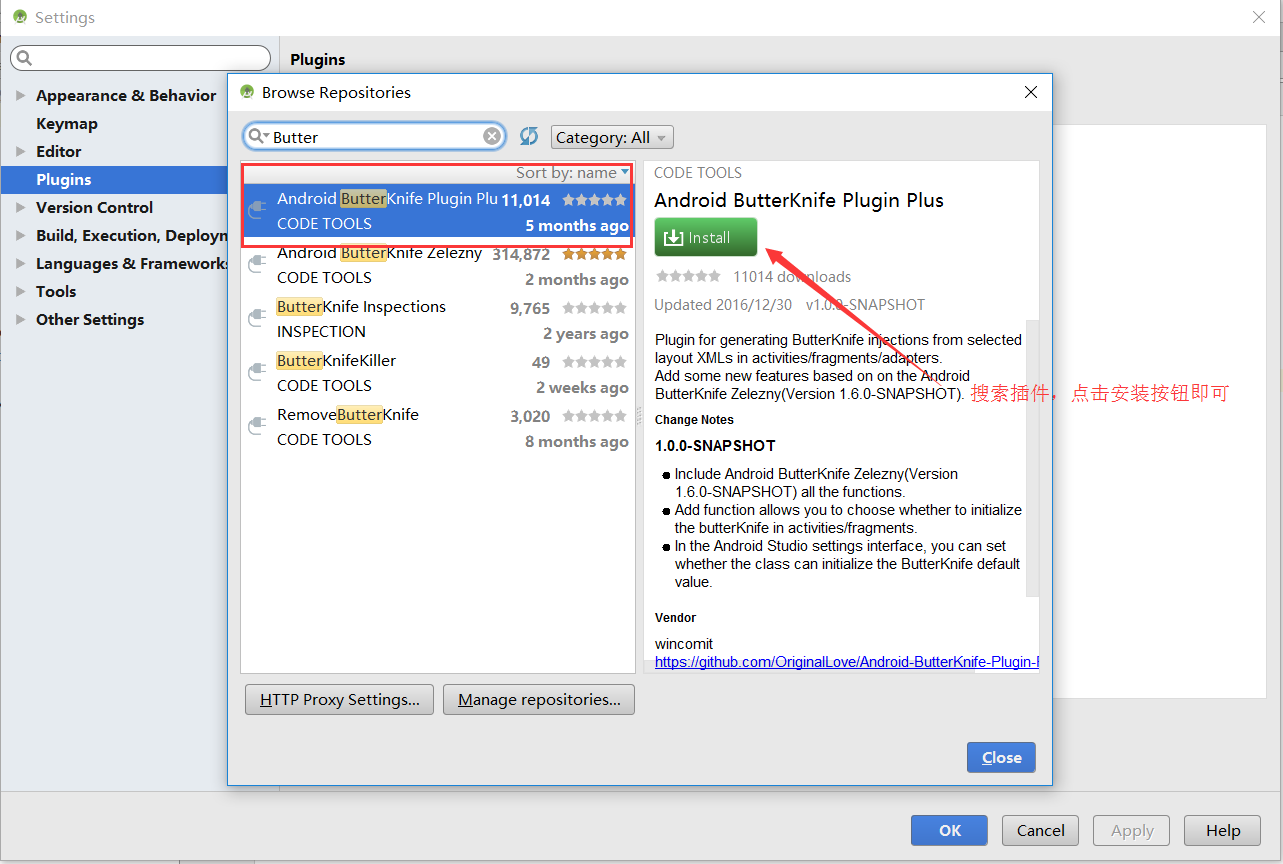
插件的使用,如下图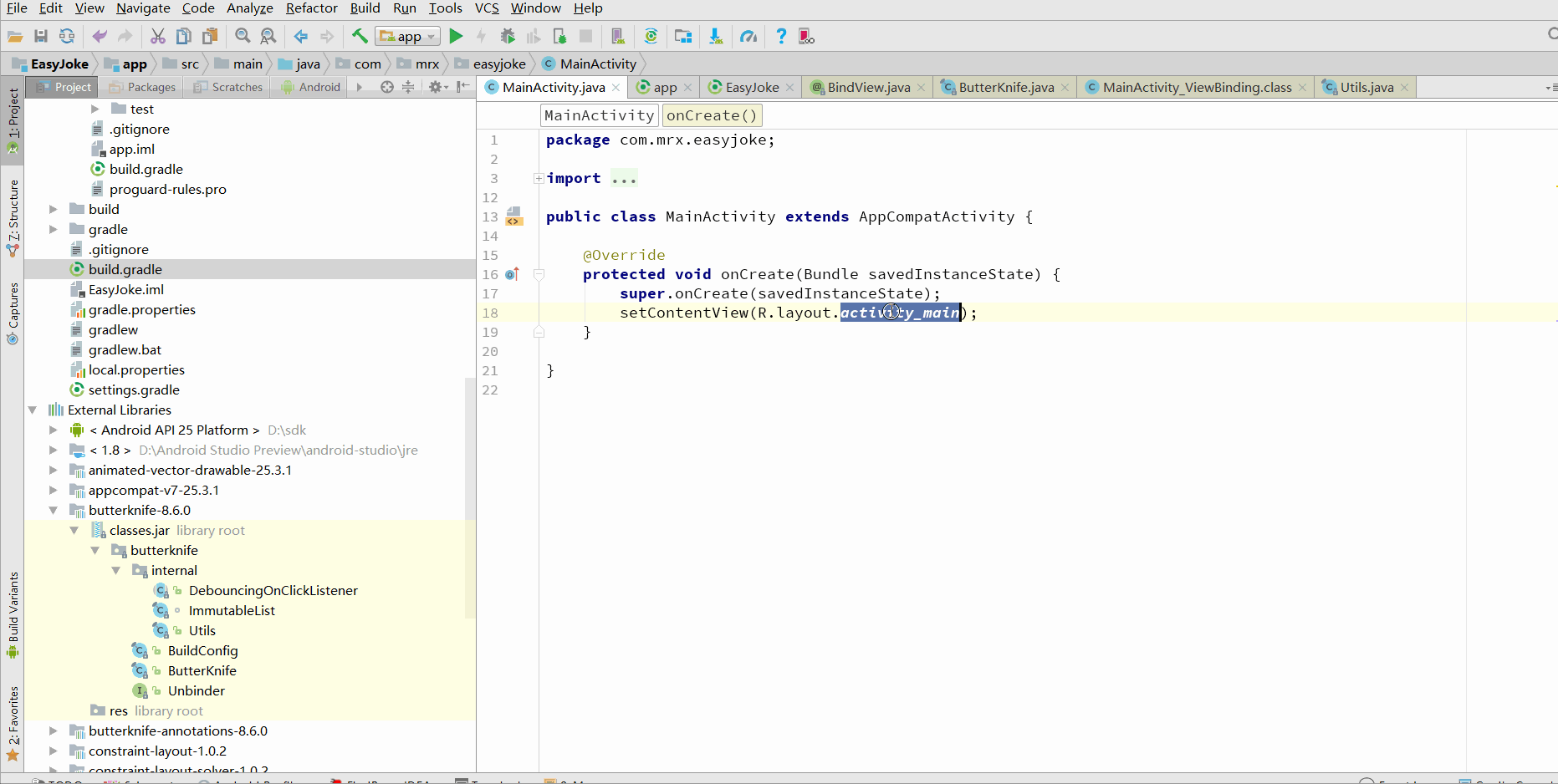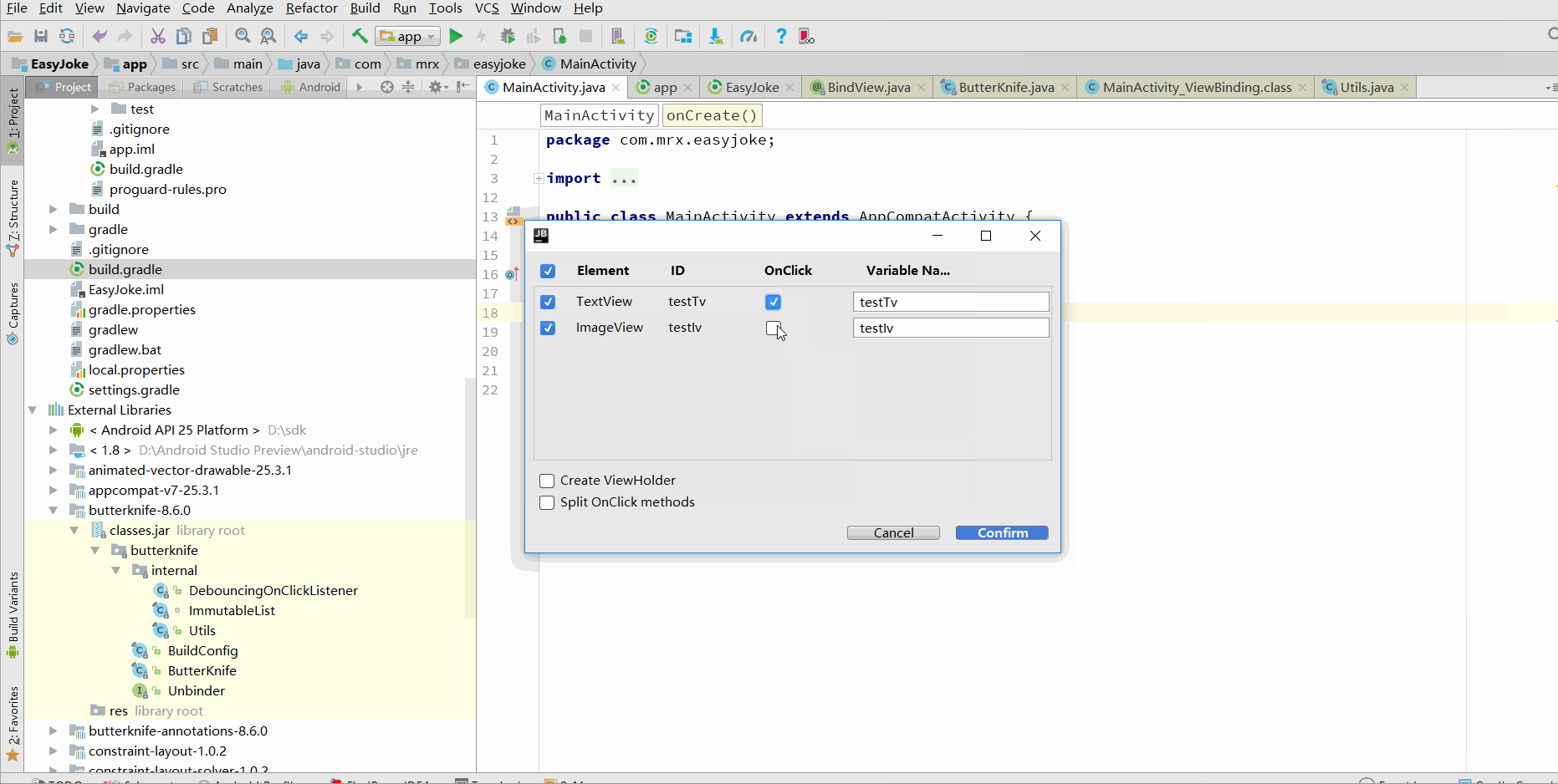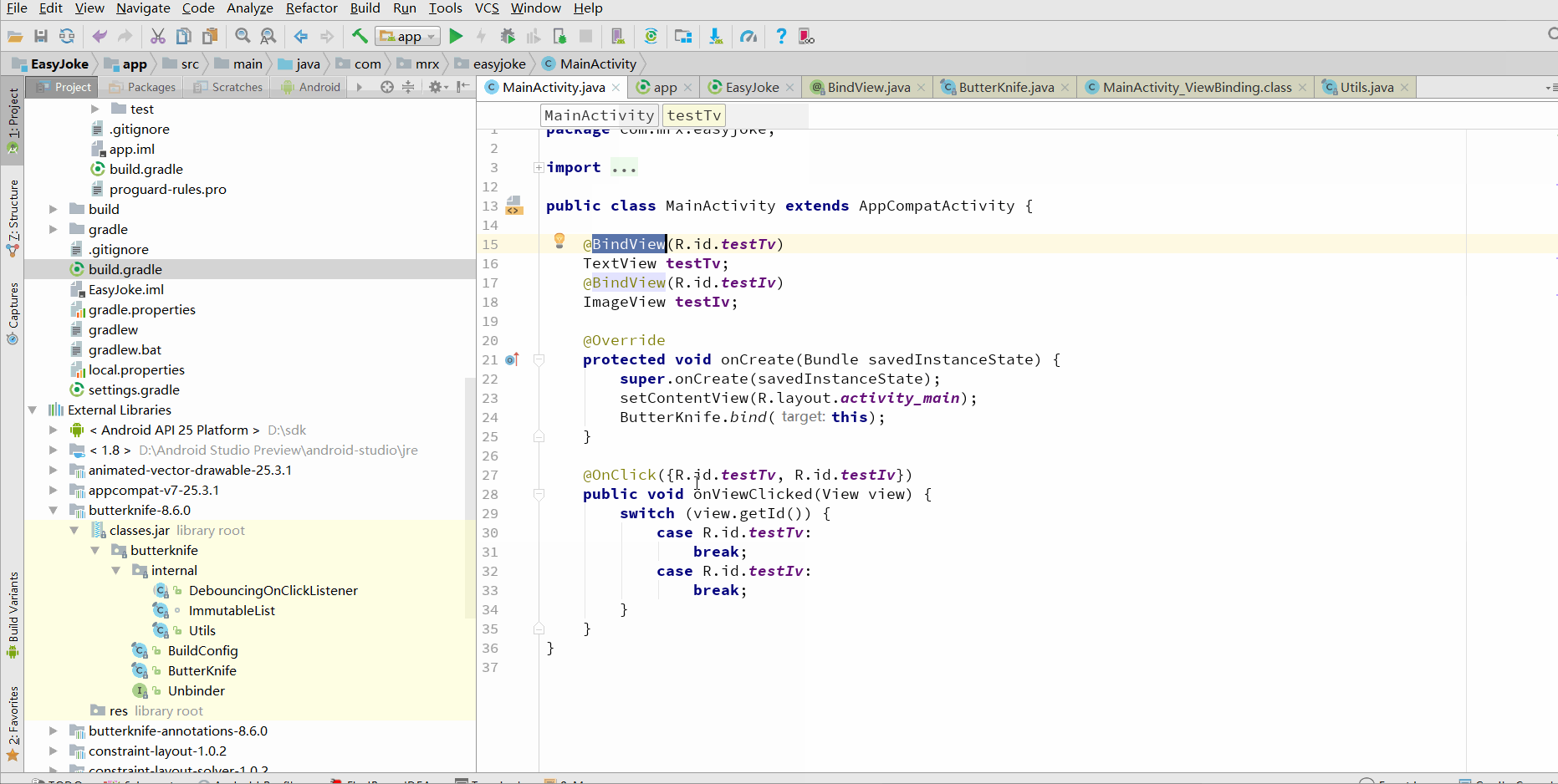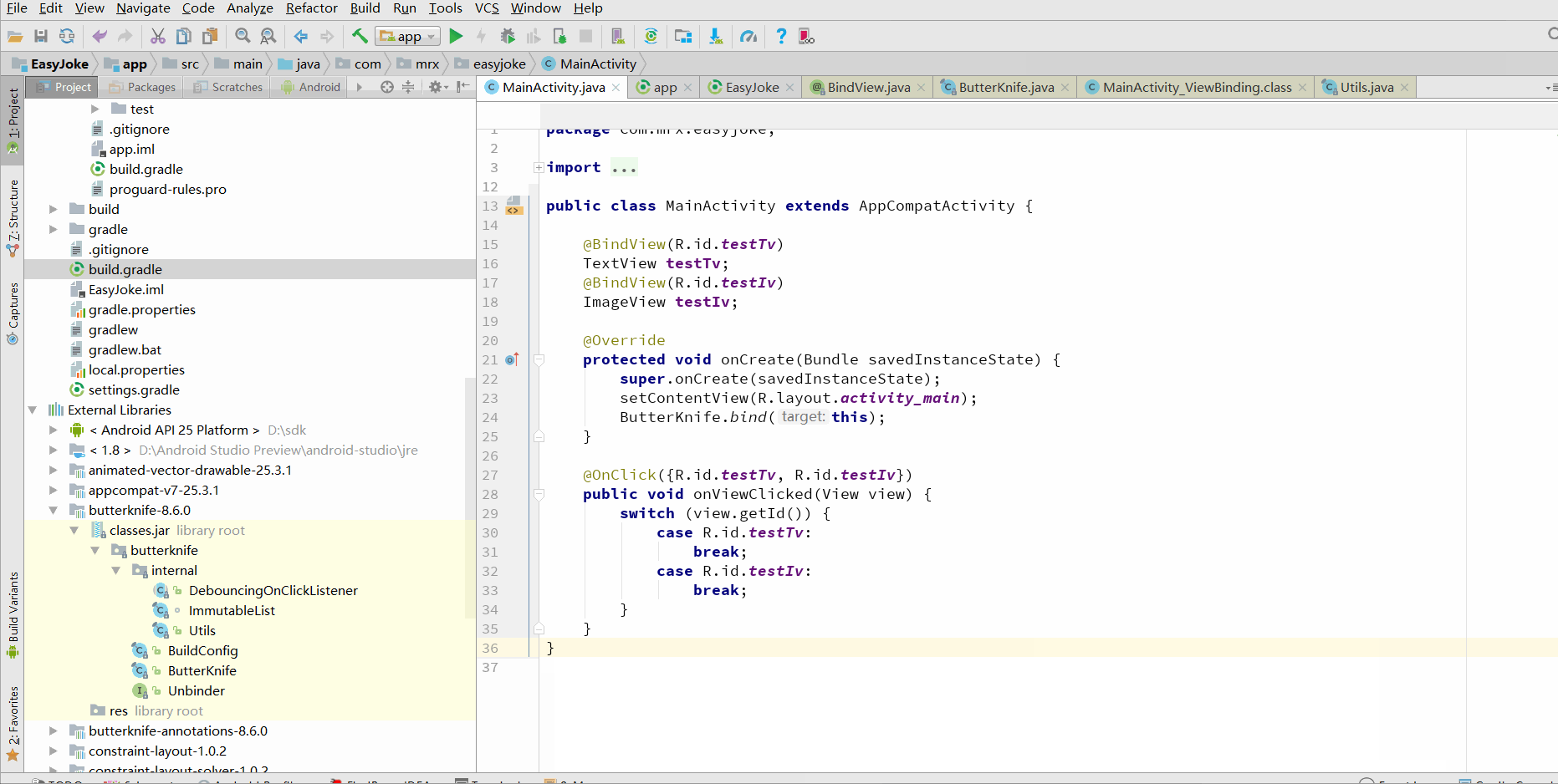
刚开始接触butterKnife的时候,只是觉得使用起来好爽啊,终于告别了findviewbyid这种体力活了,飞一般的感觉。但是butterKnife是如何实现的呢?那么接下来,让我们搞起来吧。致敬大神🙏。
需要了解的知识
下面列出的知识点,如有疑问强烈建议大家查看
1 Java注解
2 Java注解处理器(这里有英文原版)
3 Java反射机制(查看本站Java反射学习实践)
4 android Gradle2.2发布更新提供的annotationProcessor功能(之前的APT)
其实学习完源码之后,你才会了解到JakeWharton大神的英雄池到底有多深!
注解
虽然上面建议大家去了解Java注解和注解处理器相关知识,但是还是决定简单介绍下相关知识吧💕
注解的定义
注解简单来说,存储一些我们需要的数据,在编译时或者运行时调用
注解(也被成为元数据)为我们在代码中添加信息提供了一种形式化的方法,使我们可以在稍后某个时刻非常方便地使用这些数据。 ——————摘自《Thinking in Java》page.620
注解的分类
####按照Java5提供的标准来分类
1 内置注解(三种)
- @override(大家比较常见)【表示当前方法定义将重写的父类方法,如果编写有误编译器发出错误提示】
- @Deprecated【表示元素废弃】
- @SuppressWarnings【关闭编译器警告】
2 元注解(四种)【负责注解其他注解】
- @Retention
- @Target
- @Documented
- @Inherited
元注解的概念稍微有一点绕,他主要用使用自定义注解时,注解你定义的注解。额 貌似还是一样的感觉,不过可以多敲代码理解下。
@Retention 表示注解将会被运行在什么时期。
用@Retention(RetentionPolicy.CLASS)修饰的注解,表示注解的信息被保留在class文件(字节码文件)中当程序编译时,但不会被虚拟机读取在运行的时候;
用@Retention(RetentionPolicy.SOURCE )修饰的注解,表示注解的信息会被编译器抛弃,不会留在class文件中,注解的信息只会留在源文件中;
用@Retention(RetentionPolicy.RUNTIME )修饰的注解,表示注解的信息被保留在class文件(字节码文件)中当程序编译时,会被虚拟机保留在运行时,
@Target 表示注解将被用在什么地方
可用的ElementType参数有:CONSTRUCTOR(构造方法),FIELD(域声明),LOCAL_VARIABLE(局部变量声明),METHOD(方法声明),PACKAGE(包声明),PARAMETER(参数声明),,TYPE(类,接口,或enum)
如果你想要你的注解在运行时起作用,并且只能修饰一个类,那你可以这样定义
@interface 是你在定义注解的时候必须在类的开头使用的限定符
按照取值的方式分类
1 运行时注解
在程序运行时可以使用。如何在运行时使用呢?当然是利用反射。retrofit框架如果查看过源码,你会发现它使用的就是运行时注解。
2 编译时注解
反射由于它的消耗较大,所以一直以来被诟病,所以。。。,那么如何使用编译时注解呢?那么下面需要了解下注解处理器的概念
注解处理器(本小节摘自Jlog`s Java注解处理器)
注解处理器概念
注解处理器(Annotation Processor)是javac的一个工具,它用来在编译时扫描和处理注解(Annotation)。你可以对自定义注解,并注册相应的注解处理器。
注解处理器的作用
一个注解的注解处理器,以Java代码(或者编译过的字节码)作为输入,生成文件(通常是.java文件)作为输出。这具体的含义什么呢?你可以生成Java代码!这些生成的Java代码是在生成的.java文件中,所以你不能修改已经存在的Java类,例如向已有的类中添加方法。这些生成的Java文件,会同其他普通的手动编写的Java源代码一样被javac编译。
虚处理器AbstractProcessor
|
|
- init(ProcessingEnvironment env): 每一个注解处理器类都必须有一个空的构造函数。然而,这里有一个特殊的init()方法,它会被注解处理工具调用,并输入ProcessingEnviroment参数。ProcessingEnviroment提供很多有用的工具类Elements, Types和Filer。后面我们将看到详细的内容。
- process(Set<? extends TypeElement> annotations, RoundEnvironment env): 这相当于每个处理器的主函数main()。你在这里写你的扫描、评估和处理注解的代码,以及生成Java文件。输入参数RoundEnviroment,可以让你查询出包含特定注解的被注解元素。后面我们将看到详细的内容。
- getSupportedAnnotationTypes(): 这里你必须指定,这个注解处理器是注册给哪个注解的。注意,它的返回值是一个字符串的集合,包含本处理器想要处理的注解类型的合法全称。换句话说,你在这里定义你的注解处理器注册到哪些注解上。
- getSupportedSourceVersion(): 用来指定你使用的Java版本。通常这里返回SourceVersion.latestSupported()。然而,如果你有足够的理由只支持Java 6的话,你也可以返回SourceVersion.RELEASE_6。我推荐你使用前者。
注册处理器
你可能会问,我怎样将处理器MyProcessor注册到javac中。你必须提供一个.jar文件。就像其他.jar文件一样,你打包你的注解处理器到此文件中。并且,在你的jar中,你需要打包一个特定的文件javax.annotation.processing.Processor到META-INF/services路径下。所以,你的.jar文件看起来就像下面这样:
- MyProcessor.jar
- com
- example
- MyProcessor.class
- META-INF
- services
- javax.annotation.processing.Processor
打包进MyProcessor.jar中的javax.annotation.processing.Processor的内容是,注解处理器的合法的全名列表,每一个元素换行分割:
把MyProcessor.jar放到你的builpath中,javac会自动检查和读取javax.annotation.processing.Processor中的内容,并且注册MyProcessor作为注解处理器。
若对上述概念有疑问,请查看原文链接
其实如果看到这里,我猜你会说TMD,没见你分析一句源码就在撤这些概念了,兄弟放下西瓜刀,先听我说,其实如果上述概念你都明白了,那么ButterKnife的源码你阅读起来完全毫无压力。
ButterKnife源码项目结构
开始我们的源码分析,首先,源代码项目结构见下图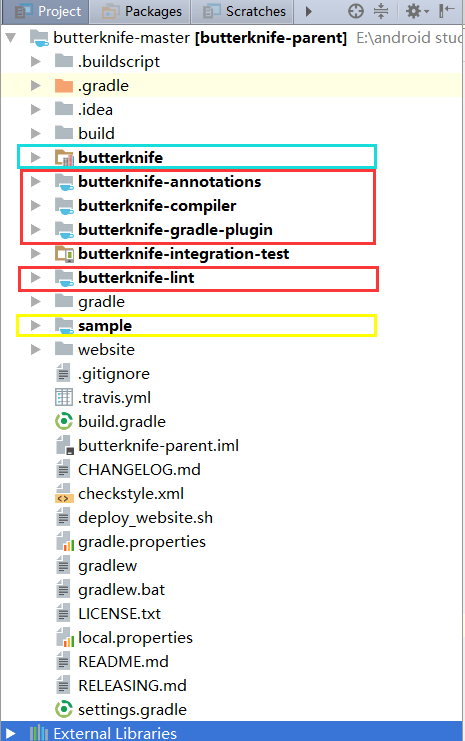
可以看到项目结构十分的明确🤸
- 蓝色框圈起的项目为android library
- 红色框圈起的项目为Java library
- 黄色框圈起的项目为demo
A 蓝色框的项目我们在dependencies中添加。提供给我们使用的API。
B 红色框的项目比较多,依次来解释
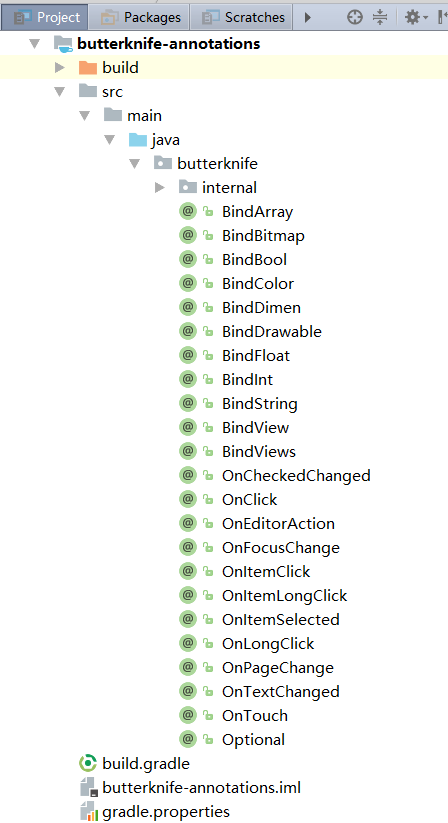
- butterknife-annotations; 定义的注解(项目结构见下图)
- butterknife-compiler;编译时用到的注解的处理器(important),细心的同学可能发现我们在项目中使用butterKnife时添加依赖的时候导入的就有这个项目
- butterknife-gradle-plugin;自定义的gradle插件,辅助生成有关代码
- butterknife-lint;项目的lint检查
C 黄色框内的demo项目暂时就不多做解释,相信大家都能看懂
ButterKnife源码学习
开始我们的正式的学习吧!
新建工程,添加ButterKnife依赖,界面很简单,包含一个TextView和IamgeView,使用ButterKnife进行注解。项目代码如下
一键生成真的是麻瓜式编程了~.~
控件的初始化和点击事件都已成功绑定了,在setContentView(…)下,多出了ButterKnife.bind(this);
@BindView
让我们首先查看下@BindView的注解是如何定义的吧。点击进入源码查看
通过上一节注解知识的学习,我们知道当前注解为编译时注解只注解参数喽,既然是编译时注解那么肯定存在注解处理器。我们在添加依赖的时候你就会发现除了ButterKnife的依赖,你同时也添加了注解处理器依赖
AbstractProcessor注解处理器
了解完@BindView源码后,接着让我们来查看下注解处理器是如何编写的。
ButterKnifeProcessor类的源码较长,这里就不贴出来了,会跳出主要的方法进行分析,如果需要,类路径为butterknife.compiler.ButterKnifeProcessor可自行查看。
- 1先来查看init()方法
|
|
首先看到的就是各种try{}catch(){},由此可见一个好的框架容错是真的厉害,基本上大部分的代码都是来处理兼容。此方法中主要获取了一些辅助类,包括元素辅助类,类型辅助类,文件辅助类等。
- 2接着查看process()方法。
|
|
这个方法就比较重要了,但是代码确如此的简单🙃,首先调用了findAndParseTargets方法返回一个Map值存放元素和对应的Bindingset,至于BindingSet是什么,暂且不表,然后遍历Map获得各个元素(注解),调用javapoet库提供的方法自动生成java类(若需了解javapoet可自行学习)。
首先我们来查看findAndParseTargets方法,
这里根据不同元素类型,调用不同的pareseBind..方法,我们仅仅查看和BindView相关的代码,其他部分代码原理相似。
接着看调用了pareseBindView
上来就又是各种校验代码。这些都不重要,哦!不对第一句
校验了修饰符,如果存在static private则抛异常,所以说我们在自己写注解的时候,要注意修饰符。
比较重要的地方有
此方法中调用了getOrCreateBindingBuilder方法
BuilderSet出现在这里,那么让我们查看BuilderSet创建调用的方法newBuilder代码如下
创建了一个builder,builder含有的参数有targetType,bindingClassName,isFinal,isView,isActivity,isDialog。参数中的bindingClassName生成需要注意下
下面就是从map中(有则取缓存,没有则创建),取出被注解变量的名称,类型,id等保存到生成的FieldViewBinding实体中,并将实体保存到build中。ok,抽根93年的雪茄压压惊。
gogogogo
接下来我们查看process()中的其他方法,
通过BindingSet获得binding,调用binding.brewJava(sdk);方法生成javaFile,通过JavaFile生成了java类,来查看下brewJava方法
这里的bindingClassName就是上面分析的newBuilder方法中赋值的bindingClassName.
也就是说会生成一个后缀名为_ViewBinding的java类。这个类位于在/build/generated/source/apt/debud/xxxx/目录下,xxx是你对应的包名。
下面为之前demo编译后生成的后缀名为_ViewBinding的java类
那么这个类是如何被调用的呢?
骚年上面我们分析了注解的生成但是有一个重要的方法被忽视了,算了,我还是重新贴下之前我们创建的项目代码吧,太长了省得大家找了
attent please!ButterKnife.bind(this);就是这个方法,来查看下bind方法进行了什么样的骚作吧,
这里主要看下调用的findBindingConstructorForClass方法,此方法返回了一个Constructor,然后通过反射生成了这个Constructor的实体,那么findBindingConstructorForClass做了什么骚作呢?
重要的方法
兄弟如果此处看不太懂,推荐你(查看本站Java反射学习实践)。这里生成的Constructor为后缀名_ViewBinding的java类,即我们在编译时生成的类。也就是说ButterKnife.bind方法会调用_ViewBinding的java类的构造函数,即本此demo中的
终于看到了熟悉的代码setOnClickListener().这里使用了回调,接着调用Utils中的方法,如下
我里个神啊,终于看到findViewById了 心好累。
其实说白了就是使用编译时注解,加动态生成Java类来完成一些重复操作,比如findViewVById和点击事件。但是,老铁,你这个框架源码是写的真的厉害
源码的暂时分析到这里吧,其实分析起来都不太难,主要的是学习源码中的处理问题的方式。当然还有编码风格色剂模式。

